
Thanks to Large Language Models (or LLMs for short), Artificial Intelligence has now caught the attention of pretty much everyone. ChatGPT, possibly the most famous LLM, has immediately skyrocketed in popularity due to the fact that natural language is such a, well, natural interface that has made the recent breakthroughs in Artificial Intelligence accessible to everyone. Nevertheless, how LLMs work is still less commonly understood, unless you are a Data Scientist or in another AI-related role. In this article, I will try to change that.
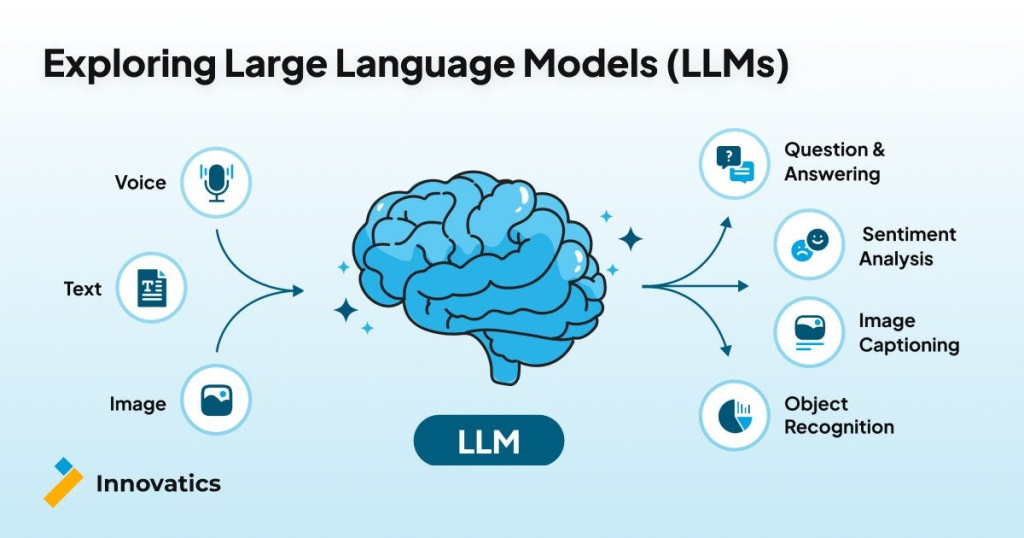
A large language model is a type of artificial intelligence algorithm that applies neural network techniques with lots of parameters to process and understand human languages or text using self-supervised learning techniques. Tasks like text generation, machine translation, summary writing, image generation from texts, machine coding, chat-bots, or Conversational AI are applications of the Large Language Model.
Examples of such LLM models are Chat GPT by open AI, BERT (Bidirectional Encoder Representations from Transformers) by Google, etc.
There are many techniques that were tried to perform natural language-related tasks but the LLM is purely based on the deep learning methodologies. LLM (Large language model) models are highly efficient in capturing the complex entity relationships in the text at hand and can generate the text using the semantic and syntactic of that particular language in which we wish to do so.
Large Language Models (LLMs) operate on the principles of deep learning, leveraging neural network architectures to process and understand human languages.
These models, are trained on vast datasets using self-supervised learning techniques. The core of their functionality lies in the intricate patterns and relationships they learn from diverse language data during training. LLMs consist of multiple layers, including feedforward layers, embedding layers, and attention layers. They employ attention mechanisms, like self-attention, to weigh the importance of different tokens in a sequence, allowing the model to capture dependencies and relationships
Architecture of LLM
Large Language Model’s (LLM) architecture is determined by a number of factors, like the objective of the specific model design, the available computational resources, and the kind of language processing tasks that are to be carried out by the LLM. The general architecture of LLM consists of many layers such as the feed forward layers, embedding layers, attention layers. A text which is embedded inside is collaborated together to generate predictions.
Important components to influence Large Language Model architecture:
- Model Size and Parameter Count
- input representations
- Self-Attention Mechanisms
- Training Objectives
- Computational Efficiency
- Decoding and Output Generation
LLM architecture explained
The overall architecture of LLMs comprises multiple layers, encompassing feedforward layers, embedding layers, and attention layers.
These layers collaborate to process embedded text and generate predictions, emphasizing the dynamic interplay between design objectives and computational capabilities.
LLM architecture diagram
Here’s the emerging architecture for LLM applications
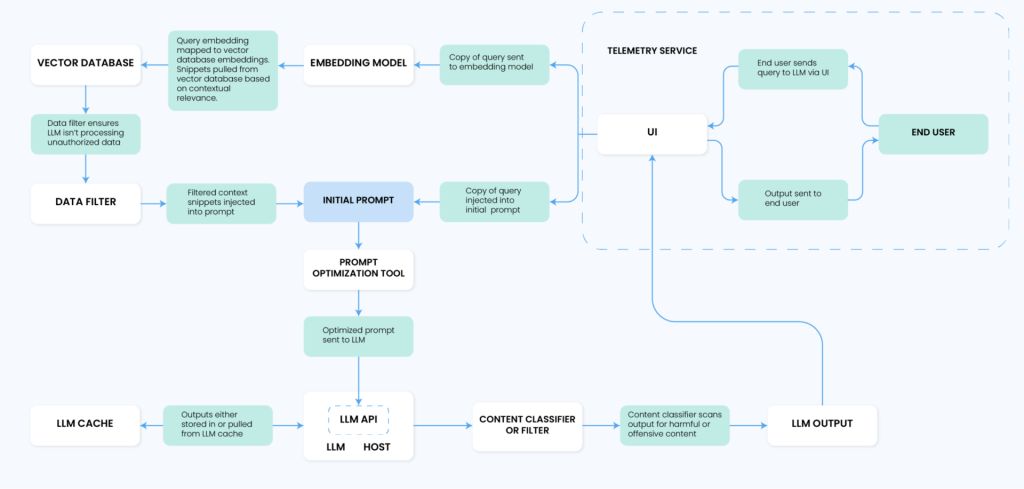
Here’s another LLM system server architecture:
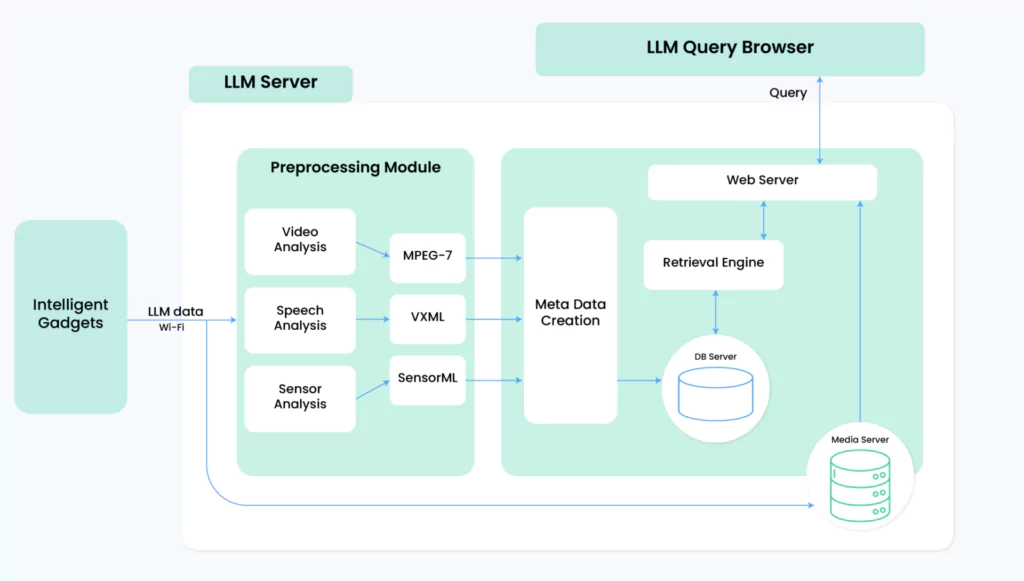
We will learn more on further posts, stay tuned.